前言
本文介绍了有关数据不均衡分布的问题,包括解决该类问题的主要方法。
1. 动机(motivation)
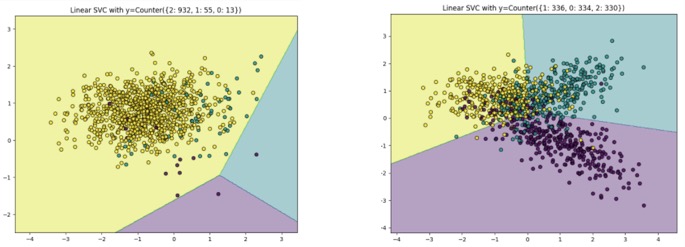
机器学习中分类问题存在许多数据样本不均衡的问题,特征的分类平面会向少数类方向偏移,不利于机器学习任务。因此,我们需要调整数据分布形成平衡的数据集,再进行特征学习。
2. 产生原因
- 内部:the nature of the dataspace,数据本身存在的分布不均衡(医学上的问题),例如患病率导致在人群中的分布不均衡
- 外部:采样的方式(比例不同)
- 相对关系:相对majority不平衡
- 绝对少数
- 类间和类内的不平衡:Between-class and inter-class imbalance
- 具有相同label的小簇
3. 采样的问题
3.1 降采样和过采样
- 随机降采样(Random Under-sampling)
减少大多数类别的数量(Cut the majority),有可能会导致丢失大类内重要的数据。
- 随机过采样(Random Oversampling):扩展小类别,就是通过有放回的抽样,不断的从少数类的抽取样本,数据重复的方式可能会导致过拟合现象。
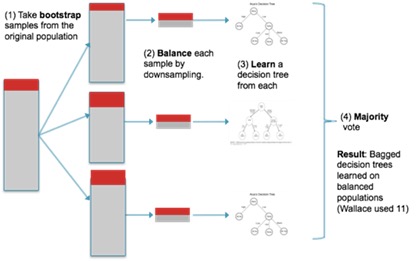
3.2 bagging+降采样
-
从大类中采样进行bagging,降采样后与少数具有相同的尺寸大小。
-
训练多个平衡的分类器,形成ensemble网络。
-
融合所有平衡的分类器的输出。
3.3 EasyEnsemble(AdaBoost+bagging)
(X.Y. Liu, J. Wu, and Z.H. Zhou, ICDM, 2006)
类似上述过程,主要差异在训练一系列AdaBoost的Ensembles网络
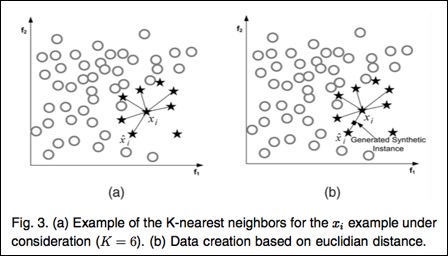
3.4 过采样(SMOTE)
Synthetic minority oversampling technique (SMOTE)
-
计算点p在S中的k个最近邻。
-
有放回地随机抽取R≤k个邻居。
-
对这R个点,每一个点与点p可以组成一条直线,然后在这条直线上随机取一个点,就产生了一个新的样本,一共可以这样做从而产生R个新的点。
-
将这些新的点加入S中连线上插值产生数据。
- 缺点:
- 过度生成数据,盲目的扩展少数类而不去考虑大类;
- 少数类可能非常稀疏化,导致类别的混淆。
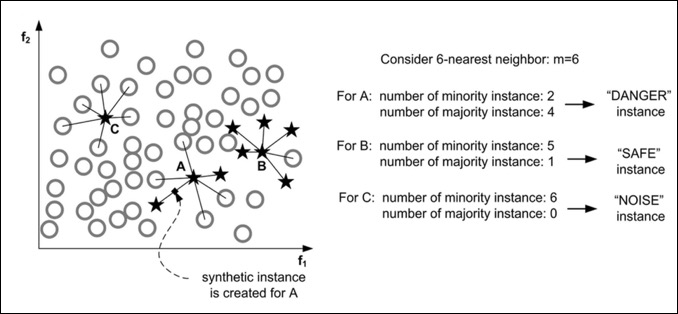
3.5 Borderline-SMOTE
-
计算点p在训练集T上的m个最近邻。我们称这个集合为Mp然后设 m’= |Mp ∩ L| (表示点p的最近邻中属于L的数量);
-
If m’= m, p 是一个噪声,不做任何操作;
-
If 0 ≤m’≤m/2, 则说明p很安全,不做任何操作;
-
If m/2 ≤ m’≤ m,那么点p就很危险了,我们需要在这个点附近生成一些新的少数类点,所以我们把它加入到DANGER中。最后,对于每个在DANGER中的点d,使用SMOTE算法生成新的样本。
3.6 SMOTE+Tomek
Upsampling+Downsampling(数据清洗)

3.7 缺点
-
需要好的映射(embedding)
-
不能解决难例问题
-
class weight:1个点当0.5个点
-
新生成的点对数据分类性能并无特别提升
-
新生成有可能混淆原始分布
4. Cost-sensitive Methods
基于损失函数敏感的方法
-
类别权重调整
-
Focal Loss/hard example mining
-
Class-dependent layer: 输出层和损失层之间添加的一层
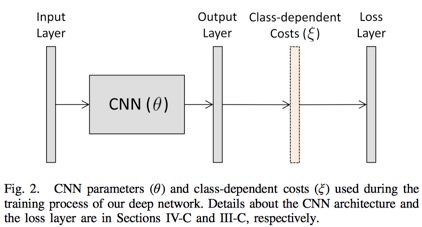
-
Rank-based Loss(损失排序)
-
instance-level re-weighting
5.metric learning methods
- triplet & quintuplet(五元组构成三个loss)
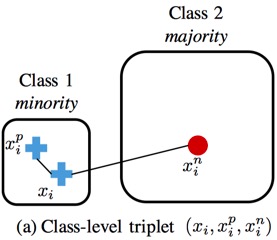
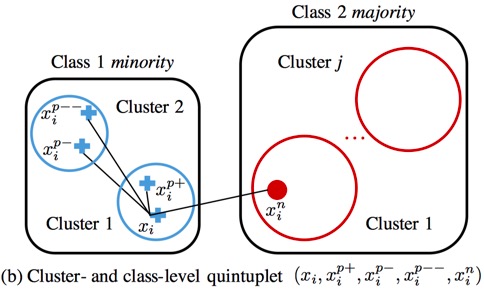
6.深度学习方法
学习embedding和分类器