前言
生成对抗网络是目前比较流行的深度学习网络结构,其包括生成模型和判别模型,在图像处理、自然语言处理等方面有显著的效果。
1. 生成对抗网络(Generative Adversarial Networks)
-
提出:
GAN启发自博弈论中的零和博弈,由Goodfellow于2014年提出
Goodfellow, Ian, et al. Generative adversarial nets.NIPS,2014.
-
两部分:
生成模型(generative model G):捕捉样本数据的分布
判别模型(discriminative model D):一个二分类器,判别输入是真实数据还是生成的样本
-
“二元极小极大博弈(minimax two-player game)”问题:
训练时固定一方,更新另一个模型的参数,交替迭代,使得对方的错误最大化
最终G 能估测出样本数据的分布,D的概率趋近$\frac{1}{2}$,无法分辨真假
目标函数:
$$\min\limits_G\max\limits_DV(D,G)=E_{p_{data}(x)}[logD(x)]+E_{p_z(z)}[log(1-D(G(z)))]$$
G使G(Z)不断接近1,最小化log(1-D(G(Z))),即最大化log(G(Z)),用来迷惑D的判断,D用来判定“赝品”,使其判断错误
D(x)代表D分辨出真实而不是生成的概率,D使log(D(x))最大化,逐渐收敛于:
$\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}$,当$p_g(x)=p_{data}(x)$,$D(x)=0.5$
-
算法流程
生成和判别模型交替进行优化

2. cGAN(conditional GAN)
Isola P, Zhu J Y, Zhou T, et al. Image-to-Image Translation with Conditional Adversarial Networks. 2016.
- 基本概念
图像处理问题可转化为:图片——图片
图片到图片的翻译(像素级)
计算机视觉:原始图片——边缘、分割、语义标签
计算机图形学:语义标签等——现实的图片
GAN学习适应数据的loss
-
基本思想
$$G:{x,z}\rightarrow y$$
目标函数:$$L(G,D)=E_{p_{data}(x,y)}[logD(x,y)]+E_{p_{data}(x),p_z(z)}[log(1-D(x,G(x,z)))]$$
在判别系统中加入原始输入图片作为监督信息
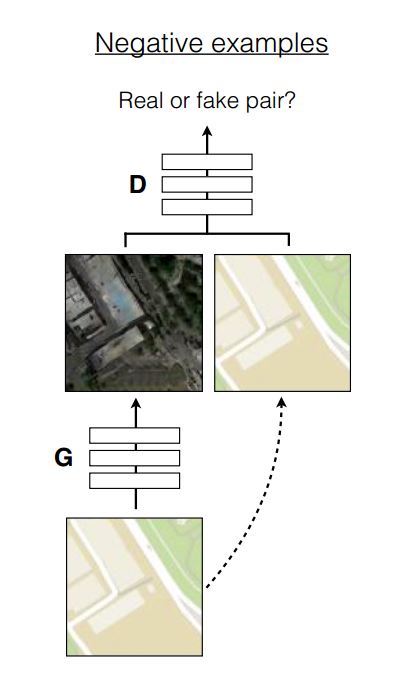
引入L1惩罚项:
$L_{l1}(G)=E_{p_{data}(x,y),p_z(z)}[\Vert{y-G(x,z)}\Vert_1]$最终的目标函数:
$G^*=arg\min \limits_{G}\max\limits_{D}L_{cGAN}(G,D)+\lambda L_{l1}(G)$ -
网络结构
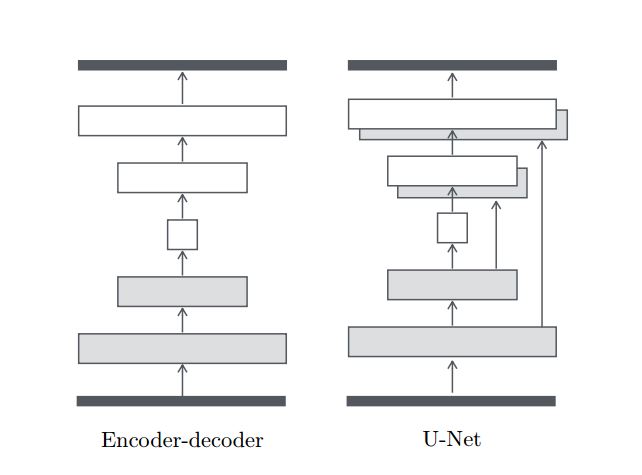
生成模型:U-net
传统编码—解码器:瓶颈区(图片与图片之间),输入和输出重叠的低层次信息冗余
U-net:跳跃连接的方式,连接i层与n-i层,共有n层
噪声采用dropout的方式
两个模型都用到:convolution-BatchNorm(块标准化)-ReLu
判别模型:卷积PatchGAN分类器
采用L1惩罚项可对低频部分有较好的修正作用
GAN鉴别器则主要负责高频部分
只针对Patch:N*N进行判定,通过卷积到全图像
优化方法:minibatch随机梯度下降法,改进方法Adam:2015.
-
实验方向
语义标签——照片:Cityscapes数据集
建筑标签——照片:CMP Facades dataset
地图——航拍照片:Google Maps
边缘——照片
素描图——照片
夜景图——白天图
BW——彩色图